REALM : Retrieval Augmented Language Model Pretraining
This paper was created by Google Research, and submitted in February 2020 and offers a new and enhanced way of language model pretraining. Also achieves SOTA on QA.
Problem : The paper starts by citing the issue with current language models and their pretraining. Bert, Roberta and T5 for example capture a great amount of world knowledge for a variety of NLP tasks however this knowledge is stored in model weights which makes it hard to interpret the model’s results and the model is not modular. To capture more knowledge one has to simply increase the numbers of parameters, data and train for longer steps which can be very costly.
Idea : To fix the issues above the paper presents a new way of pretraining language models to be as performing or better on NLP tasks with fewer parameters. The idea is fairly simple, let’s say you have a question and you want to answer it, the first thing that a human would do is to check google open a few links and find the answer. The paper mimics this kind of behaviour by introducing a Knowledge Retriever and it’s job is to act like Google so it will get relevant documents to answer a question and then a Knowledge Augmented Encoder is used to get the answer from the retrieved document.
Example :
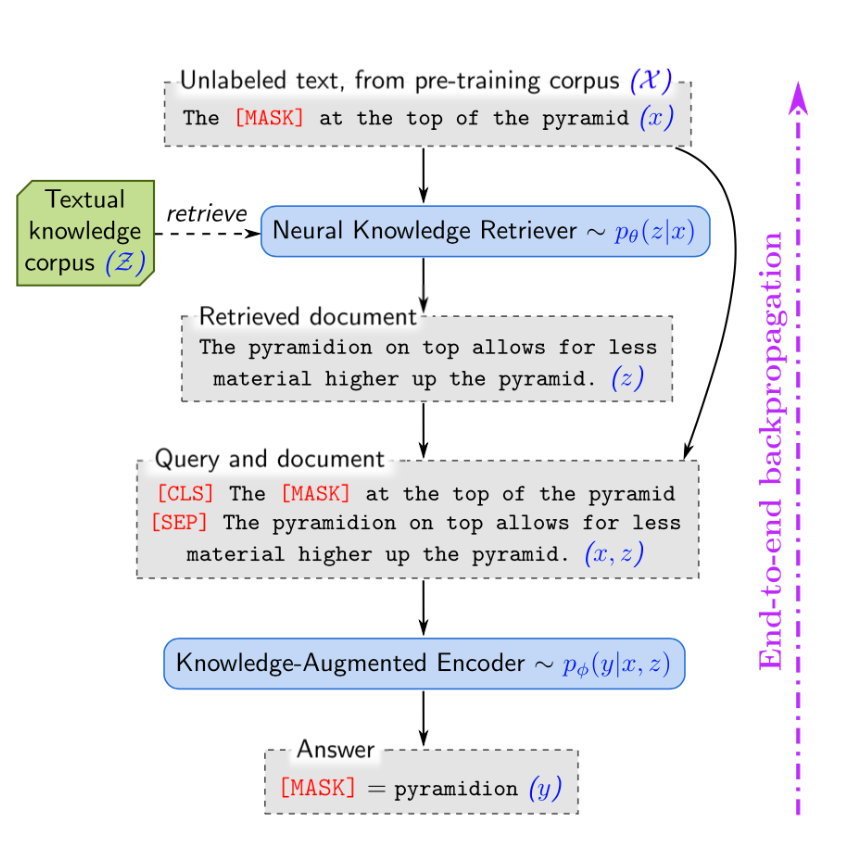
- Pre Training is done on the MLM variant of BERT.
- Fine Tuning is done on OpenQA.
For pretraining we mask random words in a sentence and the model learns to retrieve relevant documents to fill in the blanks.
OpenQA : openQA is a variant of Question Answering where the model doesn’t receive a document that is known to have the answer. Instead it will receive multiple documents the model has to learn how to filter relevant ones.
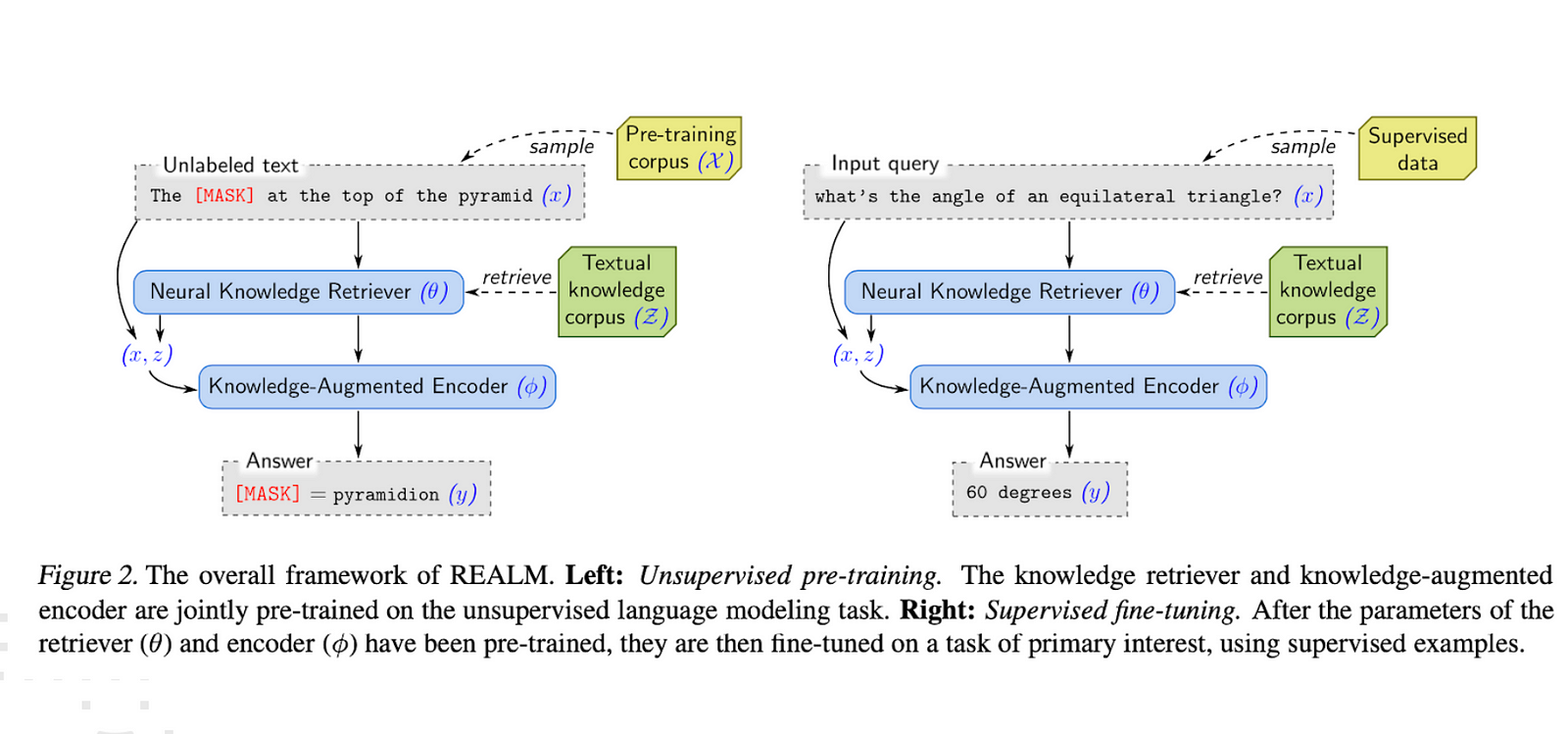
REALM decomposes p(y | x) into two steps: retrieve, then predict. Given an input x, we first retrieve possibly helpful documents z from a knowledge corpus Z . We model this as a sample from the distribution p(z | x). Then, we condition on both the retrieved z and the original input x to generate the output y — modeled as p(y | z, x). To obtain the overall likelihood of generating y, we treat z as a latent variable and marginalize over all possible documents z.
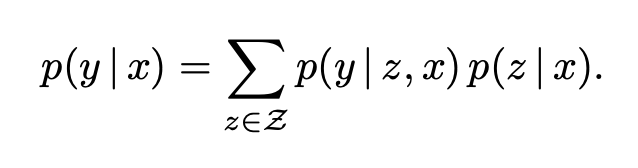
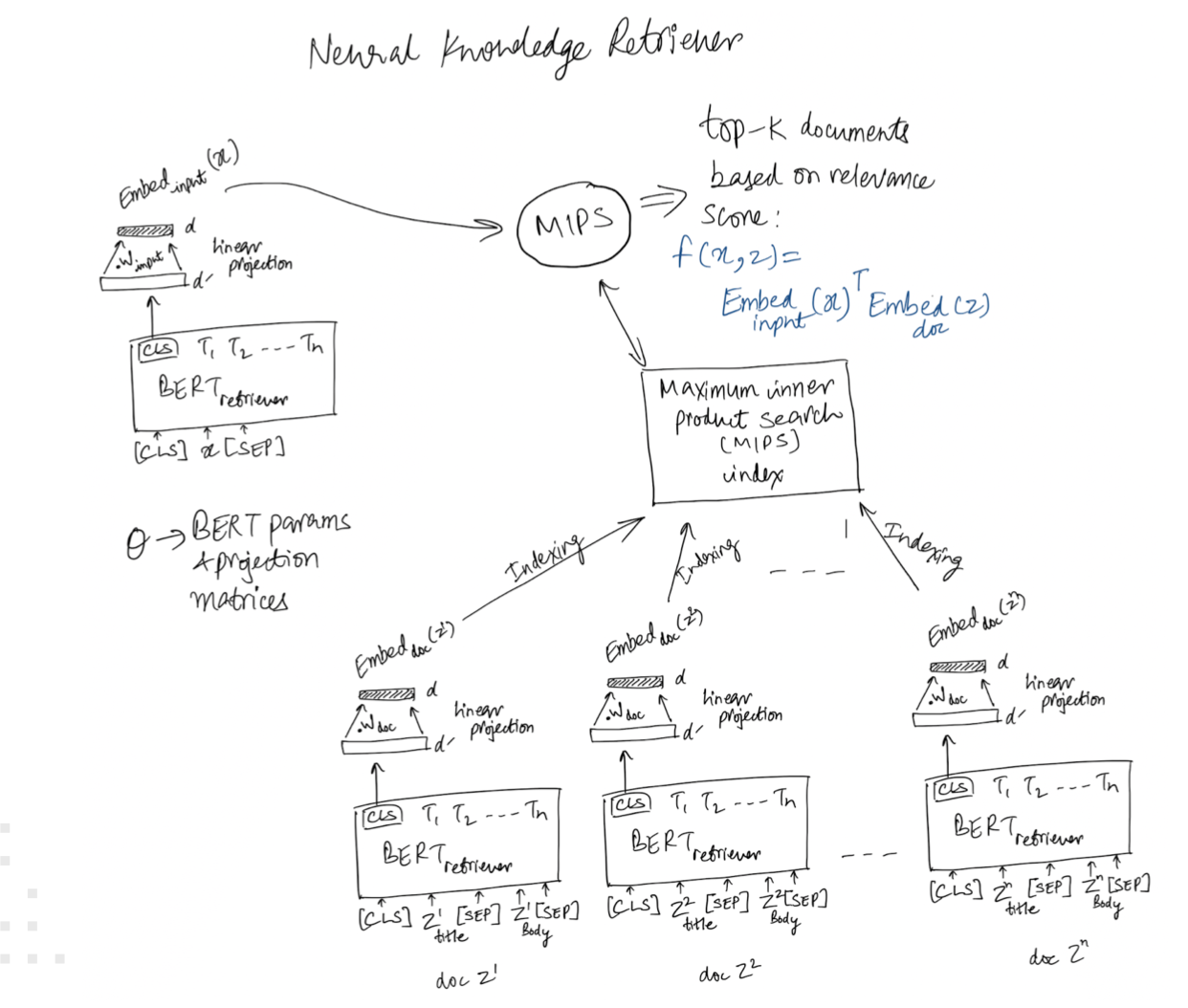
Knowledge Retriever : Let’s dive into the the details of the knowledge retriever, we are trying to model the following :
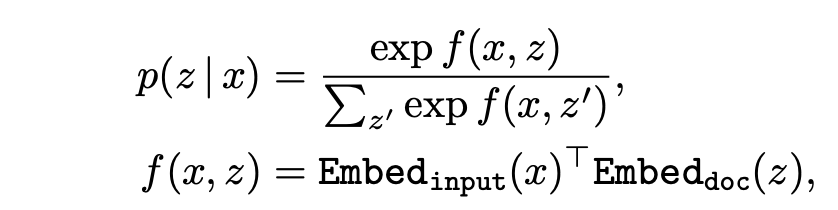
where Embedinput and Embeddoc are embedding functions that map x and z respectively to d-dimensional vectors. The relevance score f(x,z) between x and z is defined as the inner product of the vector embeddings. The retrieval distribution is the softmax over all relevance scores.
Following BERT, spans are joined using the token [SEP] and prefixed by [CLS]

The vector produced by the transformer is then retrieved by the [CLS] token so finally we get this :

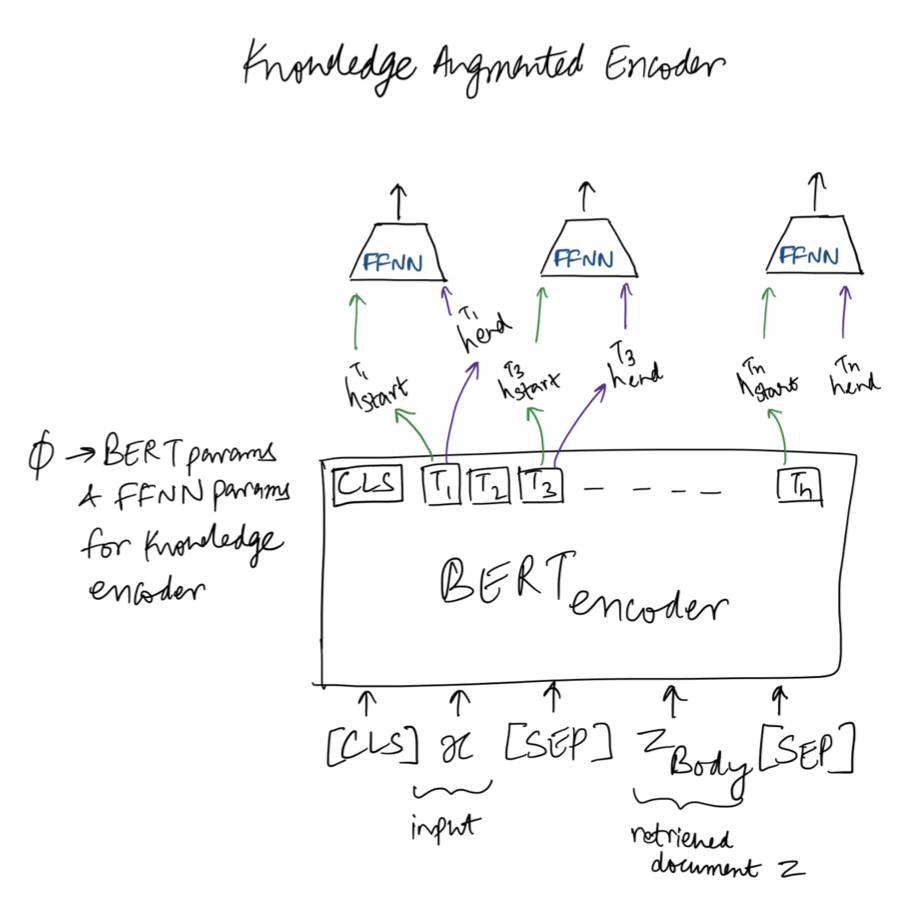
Knowledge Augmented Retriever : Now let’s look into the Knowledge augmented retriever, in case of pretraining we want to model the following :
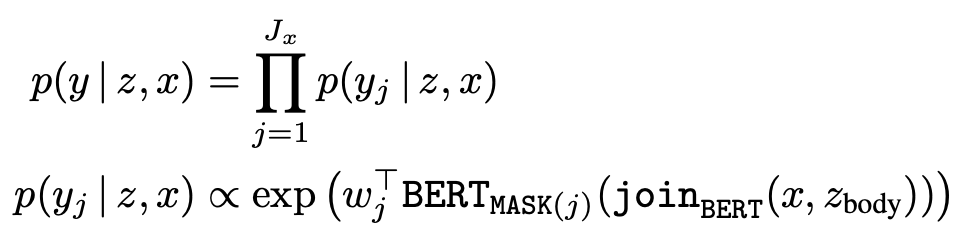
where BERTMASK(j) denotes the Transformer output vector corresponding to the jth masked token, Jx is the total number of [MASK] tokens in x, and wj is a learned word embedding for token yj.
For Fine tuning we change into this :
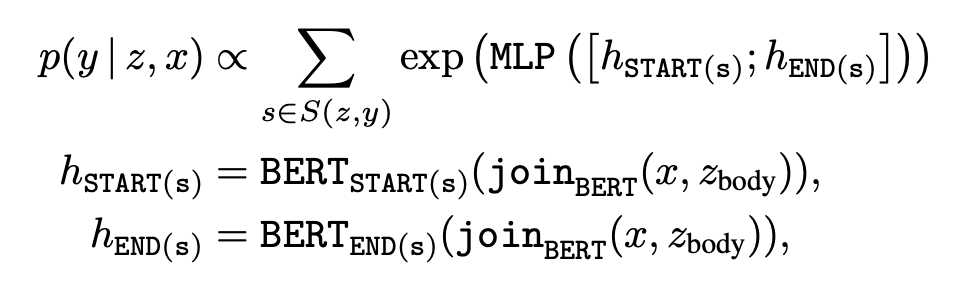
where BERTSTART(s) and BERTEND(s) denote the Transformer output vectors corresponding to the start and end tokens of span s, respectively, while MLP denotes a feed-forward neural network.
Computational challenge : The key computational challenge is that the marginal probability p(y|x)=z∈Z p(y|x,z)p(z|x) involves a summation over all documents z in the knowledge corpus Z. We approximate this by instead summing over the top k. This makes sense if most docs have near zero probability.
Solution : Find the top-k relevant docs => how do we find them efficiently ? Note that the relevance score p(z | x) is the same as the following inner product :
f(x,z) =Embedinput(x)⊤Embeddoc(z) now we can use MIPS ( Maximum inner product search) to find the top-k docs but we still have to precompute the embeddings, after a few iterations the embeddings change and the index given by MIPS become stale so we have to update them.
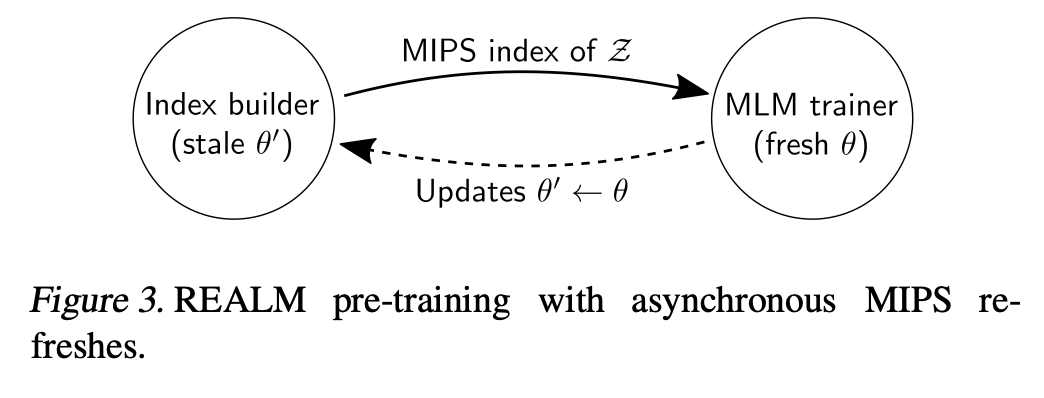
MIPS is used during pre training only, during fine tuning MIPS is computed once at the beginning using the pretrained embeddings.
What does the retriever learn ?
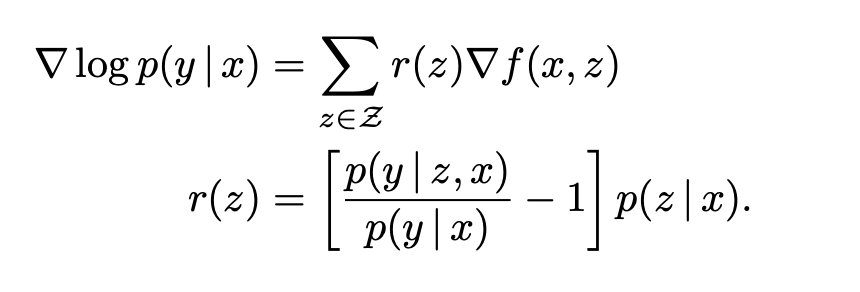
For each document z, the gradient encourages the retriever to change the score f(x,z) by r(z) — increasing if r(z) is positive, and decreasing if negative. The multiplier r(z) is positive if and only if p(y|z,x) > p(y|x). The term p(y | z, x) is the probability of predicting the correct output y when using document z. The term p(y | x) is the expected value of p(y | x, z) when randomly sampling a document from p(z | x). Hence, document z receives a positive up- date whenever it performs better than expected.
The vicious cycle :
As you may have noticed by now, being able to train this model is very hard, because if the initial embeddings aren’t good the MIPS index will be wrong, the retriever won’t learn anything. The knowledge augmented retriever will ignore retrieved documents so gradients won’t backpropagate and no learning will happen.
The paper offer a set of solutions to solve this :
- Salient Span Masking : the masking strategy is different from regular MLM, in REALM we want to focus on spans that require world knowledge. To focus on problems that require world knowledge, we mask salient spans such as “United Kingdom” or “July 1969”. We use a BERT-based tagger trained on CoNLL-2003 data to identify named entities, and a regular expression to identify dates. We select and mask one of these salient spans within a sentence for the masked language modeling task.
- Null Document : Null document is added to the corpus to add flexibility to the model and provide the option of not choosing anything.
- Prohibiting trivial retrievals : If X exists exactly in Z, this results in big gradient values for p(z|x) the model stops learning and looks for exact patterns and similarities if this occurs too often. That’s why trivial candidates are removed during pretraining.
- Initialization using Inverse Cloze Task : To help solve the vicious cycle mentioned above we provide a way to pre pretrain the embeddings using ICT where, given a sentence, the model is trained to retrieve the document where that sentence came from.
Pretraining Config :

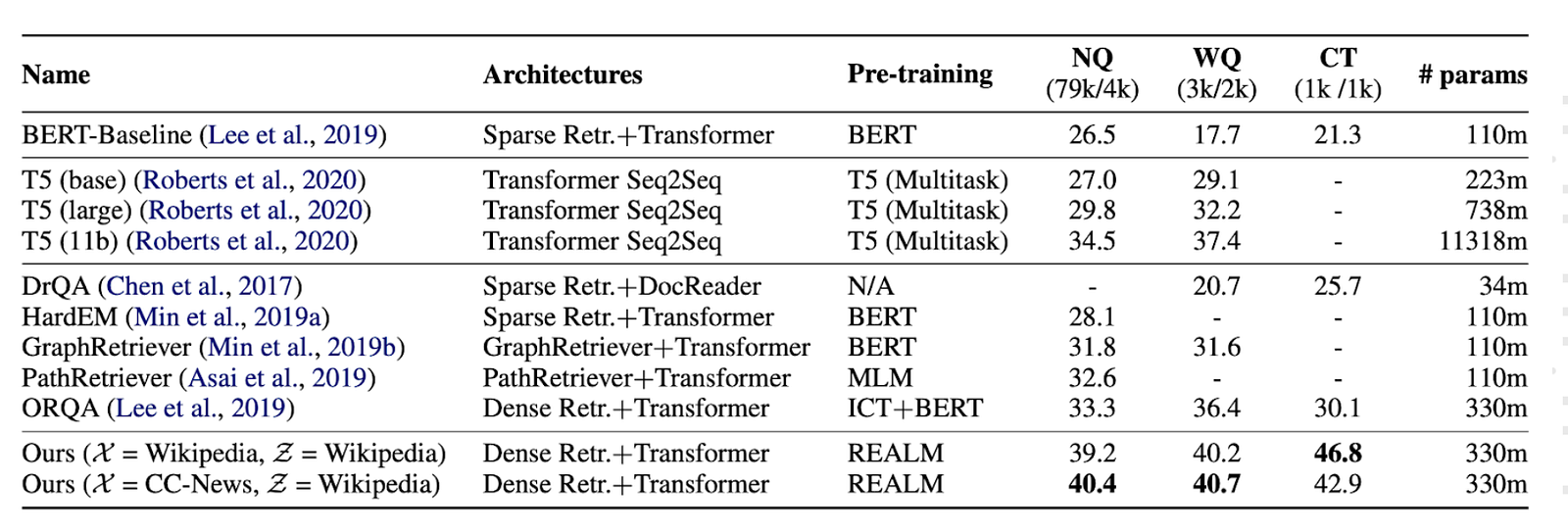
Results :
Concrete Example :

Key Takeaways :
- REALM outperforms T5 11b while being 30 times smaller.
- Salient span masking outperforms other masking strategies.
- We have to consider some hyperparameters when working with REALM such as MIPS refresh rate and top K documents to retrieve.
References :
Hope you enjoyed this interesting paper. I’m happy to discuss it further :
My linkedIn, My email : azizbelaweid@gmail.com

Comments
Post a Comment